![]()
Weka is a powerful machine learning framework. However, it lacks of tools to handle time series data analysis. TS-Classification is a package for facilitating time series classification tasks in Weka.
This package implements the following functionalities:
- DTWDistance: a distance function based on the dynamic time warping dissimilarity measure, DTW
- DTWSearch: a nearest neighbors algorithm for the classification of time series, which takes advantage of the Keogh’s lower bound technique in order to reduce the computational cost of the classification with DTW
- NumerosityReduction: a filter for numerosity reduction of time series, which is an implementation of the “Fast time series classification using numerosity reduction” algorithm for Weka.
Citation
If you use this tool, please cite the following paper:
- César Soto Valero, Mabel González Castellanos. Paquete para la clasificación de series temporales en Weka. In III Conferencia Internacional en Ciencias Computacionales e Informáticas (CICCI’ 2016), La Havana, Cuba. PDF
@inproceedings{SotoValero2016,
author = {C\'esar Soto-Valero, Mabel Gonz\'alez Castellanos},
title = {Paquete para la clasificación de series temporales en Weka},
year = {2016},
publisher = {Ediciones Futuro},
address = {Cuba},
booktitle = {III Conferencia Internacional en Ciencias Computacionales e Inform\'aticas},
pages = {1–13},
numpages = {13},
location = {La Havana, CU},
series = {CICCI' 2016}
}
Installation
To use the timeseriesClassification package, make sure you have installed Weka > 3.7.
Go to ~/wekafiles/packages and decompress the timeSeriesClassification.rar file there.
In Linux, you can do this by executing the following commands:
git clone https://github.com/cesarsotovalero/timeSeriesClassification.git
cd timeSeriesClassification
tar timeSeriesClassification -C ~/wekafiles/packages
After this, open Weka normally. The timeseriesClassification package will be automatically loaded and its features should be available through the GUI and CLI user interfaces provided by Weka.
Usage
Here, we will rely on an example to illustrate how to use the timeSeriesClassification package to classify time series data.
Classification example
Download the ECG5000 dataset.
Load the train dataset ECG5000_TRAIN.arff in the Weka explorer.
In the explorer, go to Classify and add ECG5000_TEST.arff file as the test set.
Then, configure the classifier by selecting Lazy > Ibk > Choose > DTWSearch
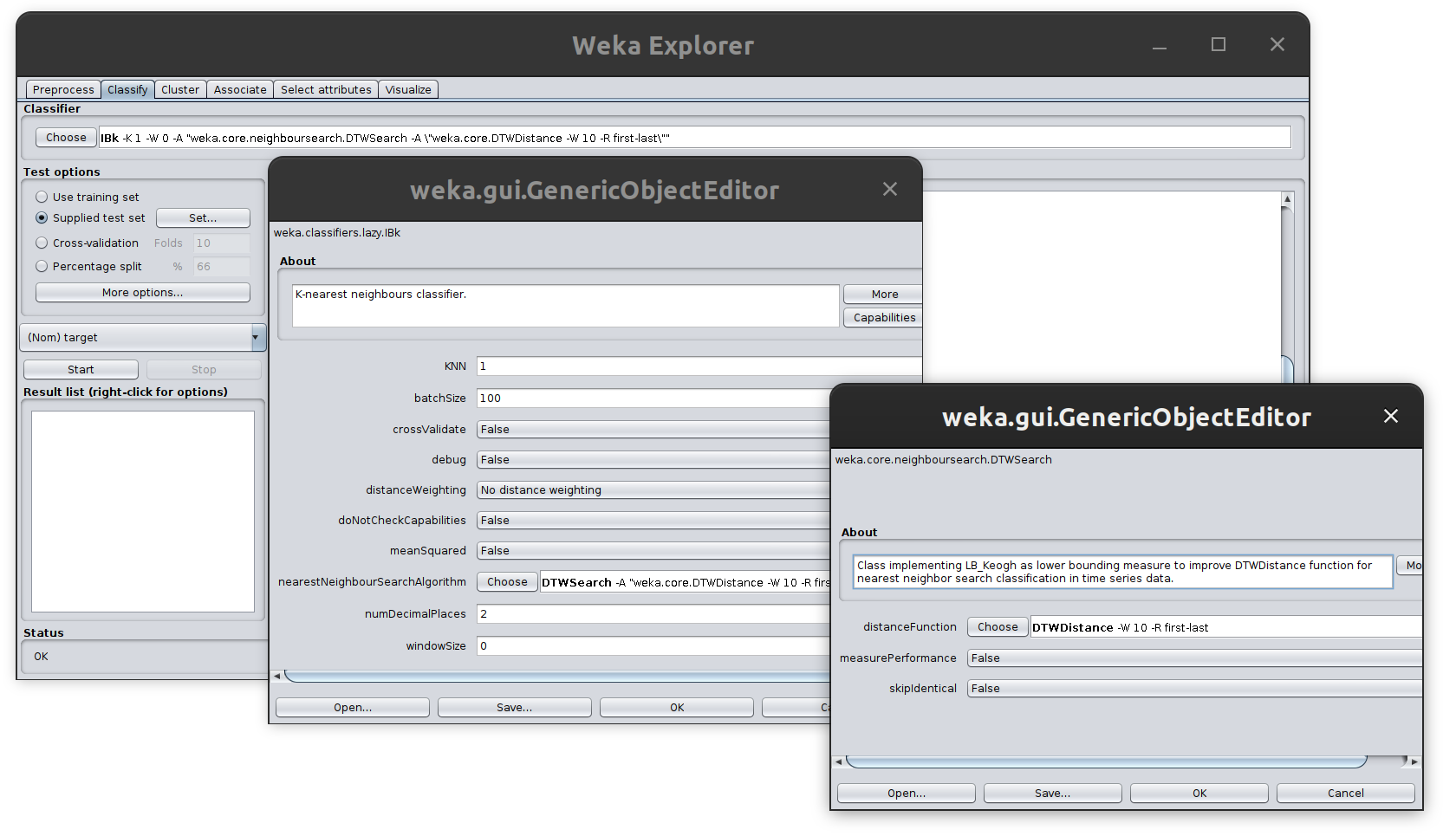
Now you can run the classifier with the DTWDistance function, you should obtain the following result:
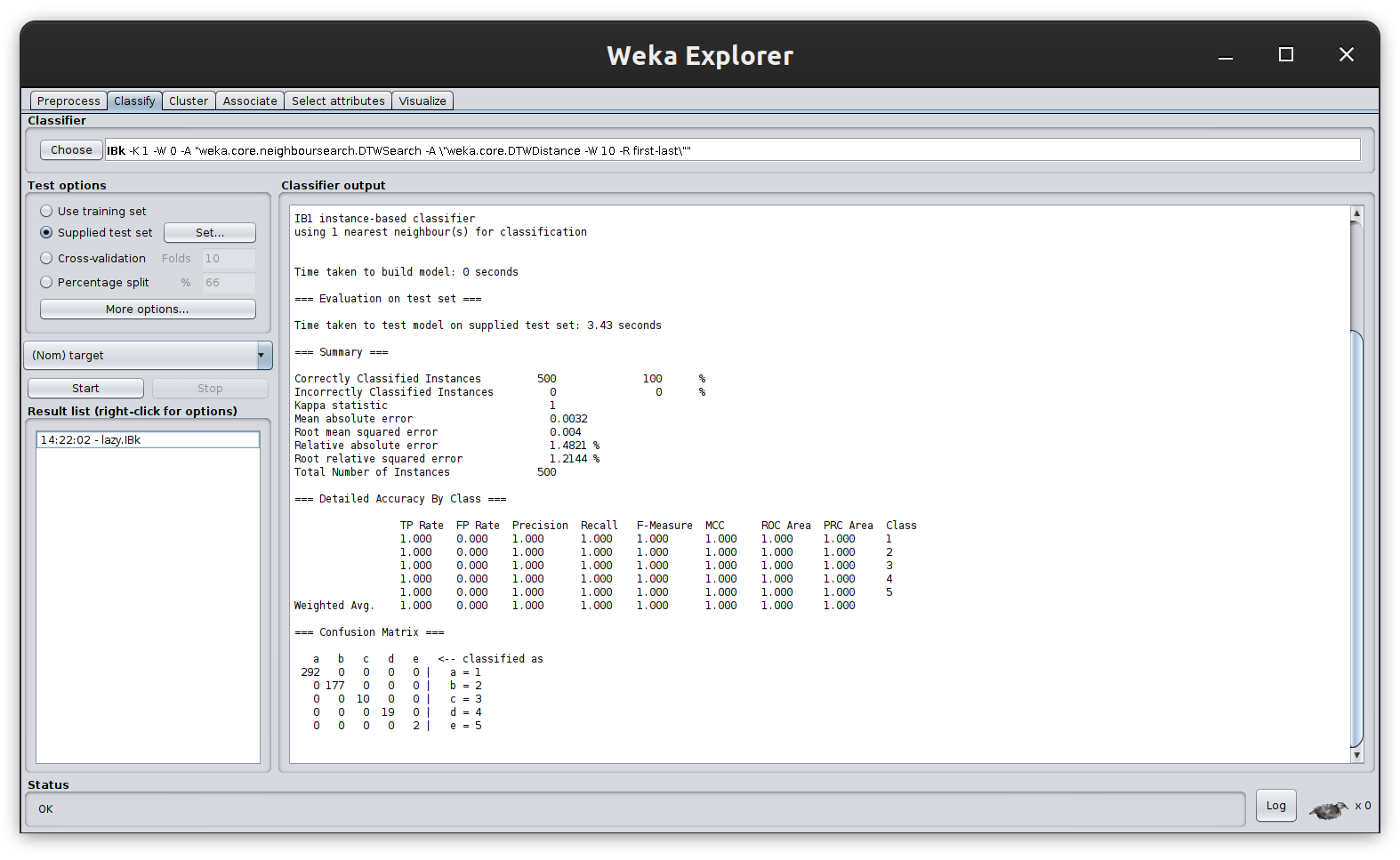
BTW, the accuracy using 1NN with the Euclidean Distance instead of DTW for this dataset is 92.2444%.
Preprocess example
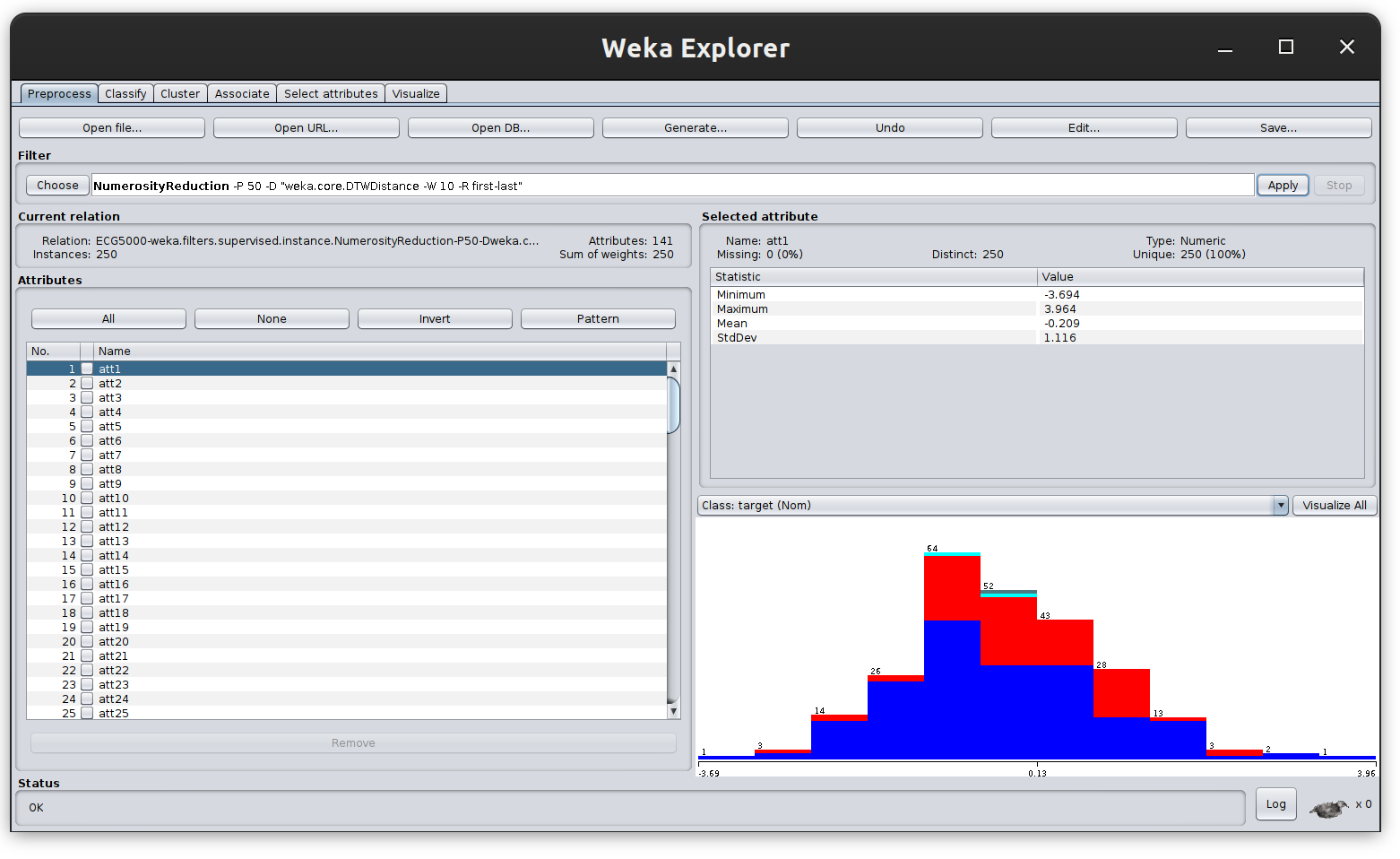
For using the NumerosityReduction filter. In the Weka explorer go to Choose > weka > filters > supervised > instance > NumerosityReduction and select the percentage of instances to be removed
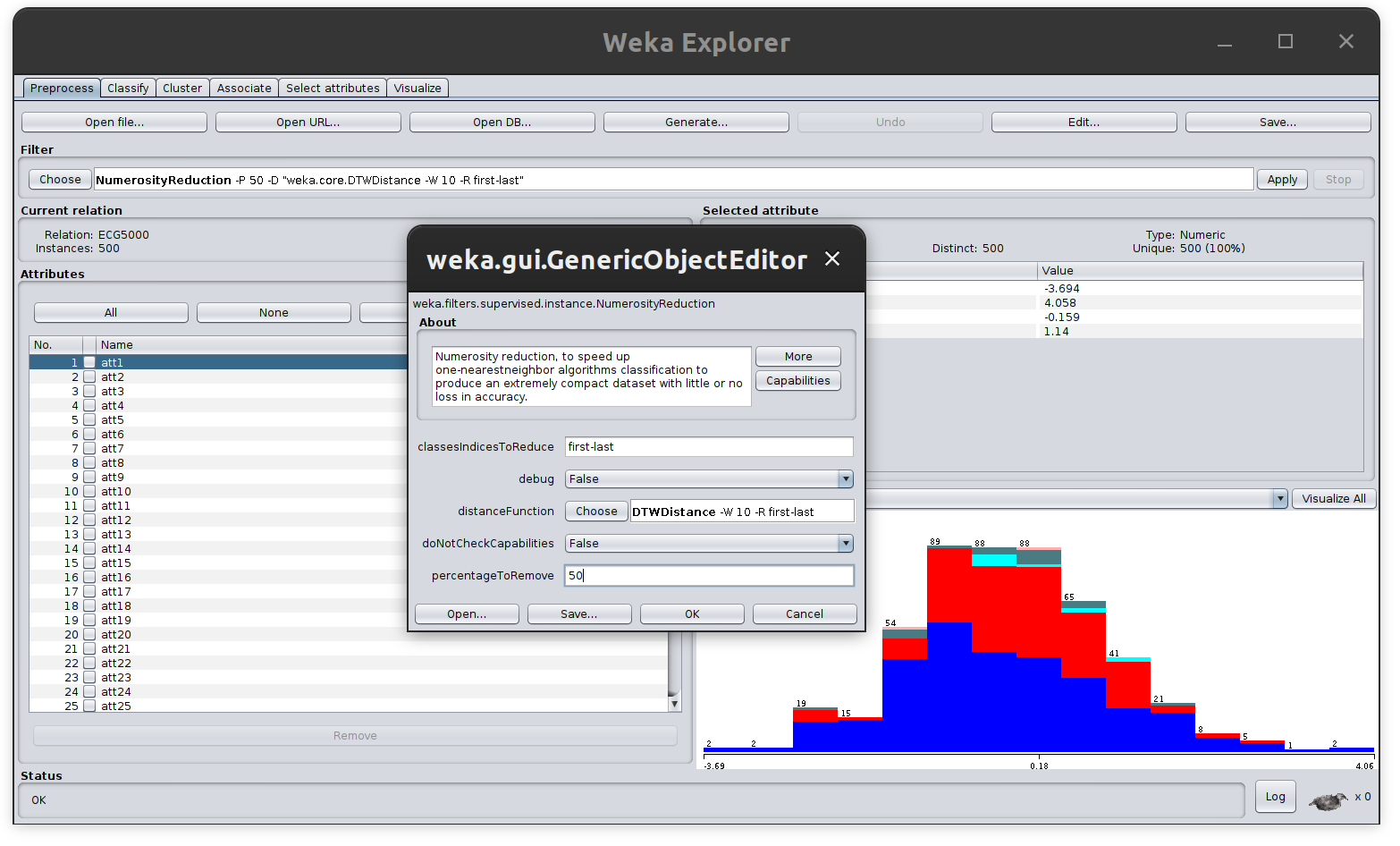
After applying the filter with percentageToRemove = 50, the dataset will contain half of the original instances, while preserving the representativeness of each one of the classes for classification